K-Nearest Neighbors Algorithm
K-Nearest Neighbors Algoritmi (bazan KNN yoki k-NN ham deb yuritiladi) parameterli bo’lmagan (non-parametric), supervised learning classifier hisoblanadi va mustaqil malumotlar nuqtalarining o’zaro bir biriga nisbatan bo’lgan yaqinligini yoki o’xshashligini hisobga olgan holda klassifikatsiyalash yoki bashorat masalalarini yechishda qo’llaniladi. Bu algoritmni regressiya yoki klassifikatsiyalash mauammolarini yechishda qo’llash mumkin bo’lsada, asosan klassifikatsiyalash masalalarida ko’proq ishlatiladi va bir biriga yaqin bo’lgan nuqtalarni bir toifaga mansub nuqtalar deb xulosa beradi.
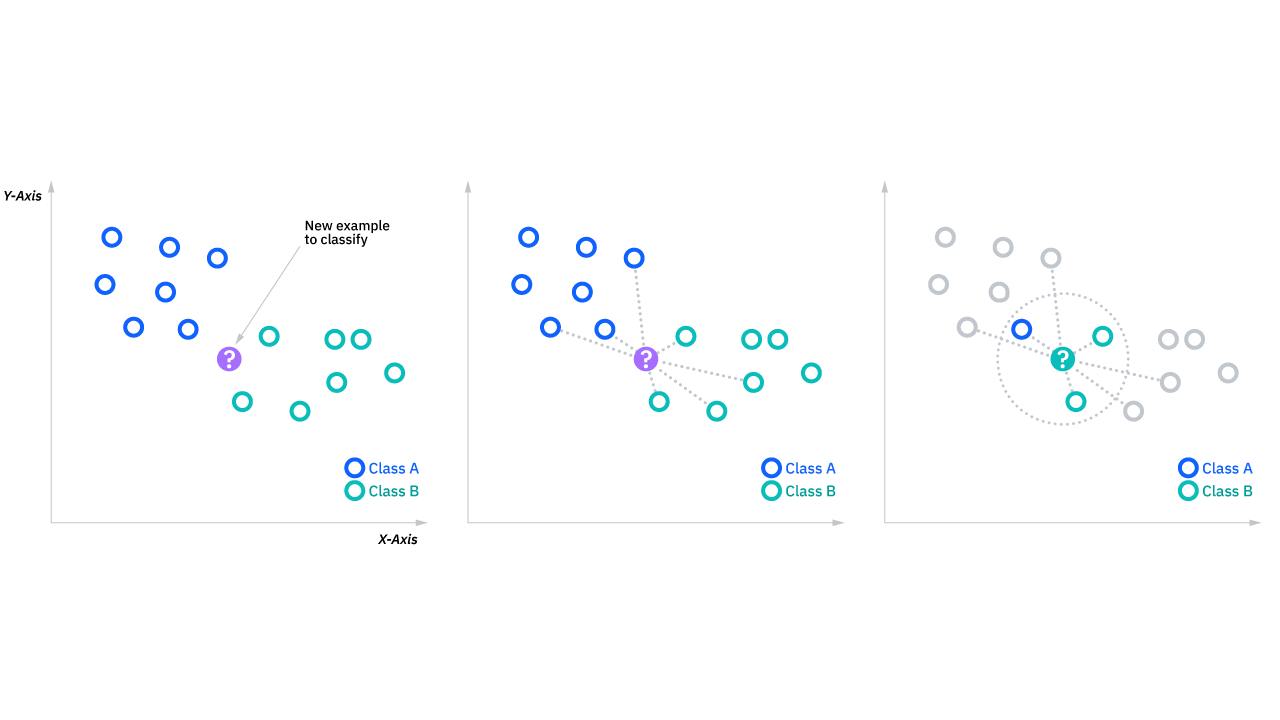
Klassifikatsiyalash masalalarida, biror bir klasni baholash ko’pchilik ovozlar hisobiga amalga oshadi. Misol uchun berilgan nuqtaning atrofida eng ko’p uchraydigan klasning yorlig’(label)iga qarab bu nuqta ham shu klasga tegishli deb hulosa qilinadi. Va bu inglizcha adabiyotlarda majority voting deb yuritiladi. Ikki kategoriyali ma’lumotlar bilan ishlaganda ko’pchilik ovozlarning soni 50% dan baland bo’lishi talab etiladi. Lekin ikkidan ortiq kategoriyaga ega ma’lumotlar bilan ishlaganda ovozlar soni 50% dan baland qilib belgilash talab etilmaydi. Misol uchun berilgan nuqtaning qaysi klasga tegishli ekanligini 25%dan baland ovoz olgan klasning yorlig’i (label) bilan belgilash mumkin.
Wisconsin-Madison Universiteti bu haqda juda yaxshi misol keltirib o’tgan (link).
Regressiya masalalari ham klasifikatsiya masalalari kabi bir xil tushinchadan foydalanadi, lekin bu holatda, klassifikatsiya haqida bashoratni amalga oshirish uchun o’rtacha k nearest neighbors tanlanadi. Bu yerda asosiy farq klasifikatsiya tavsiflovchi qiymatlar uchun ishlatiladi, regressiya esa uzluksiz qiymatlar uchun ishlatiladi. Biroq klasifikatsiya qilinishidan oldin, masofa hisoblab chiqilishi kerak. Bu holatda masofani hisoblashda eng ko’p hollarda Euclidean distance ishlatiladi, va keyinchalik bu haqda to’liqroq o’rganamiz.
Shu o’rinda yana shuni aytib o’tish kerakki KKN algoritmi lazy learning modellar oilasiga mansub bo’lib, bu shuni anglatadiki u faqat o’qitish jarayoni davom etayotgan bosqichga qarshi training datasetni saqlaydi. Bu yana shuni anglatadiki hamma hisoblashlar klassifikatsiya yoki bashorat qilish jaroyoni bo’layotganda amalga oshadi. U hamma o’qitilgan ma’lumotlarni saqlash uchun xotiraga juda chuqur bog’langanligi uchun instance-based yoki memory based o’qitish usuli ham deb yuritiladi.
U hozir avvalgidek mashxur bo’lmasada, soddaligi va aniqligi sababli data scienceda hali ham eng birinchi o’rganiladigan algoritmlardan bittasi hisoblanadi. Biroq, ma’lumotlar to’plami o’sib borgan sari, KNN tobora samarasiz bo’lib boradi va modelning umumiy ishlashiga salbiy tasir etadi. U odatda sodda tavsiya qilish tizimlari, ketma-ketliklarni aniqlash, data mining, moliya bozorini bashorat qilish, raqamli (electron) hujumlarni aniqlash va shu kabi tizimlarni yaratishda ishlatiladi.
KNNni hisoblash: Masofa o’lchovchilari (distance metrics)
Eslatib o’tamiz, k-nearest neighbor algorithmning maqsadi izlanayotgan nuqtaning eng yaqin qo’shnilarini aniqlashdan iboratdir va shundagina biz izlanayotgan nuqtaning qaysi klasga tegishli ekanligini belgilay olamiz. Buni amalga oshirish uchun KNNning bir nechta talablari bor:
KNNni hisoblash: Masofa ko’rsatkichlari
Berilgan nuqtalarga eng yaqin ma’lumotlar nuqtalari qaysilari ekanligini aniqlash uchun, berilgan nuqta va qolgan ma’lumotlar nuqtalari orasidagi masofalarni aniqlash kerak bo’ladi. Shu masofalar ko’rsatkichlari so’ralayotgan nuqtalarni turli guruhlarga ajratadigan chegaralarni chizishga yordam beradi.
Masofa ko’rsatkichlarini aniqlaydigan bir qancha usullari bo’lsada bularning orasidan bazilarini ko’rib chiqamiz
Euclidean distance (p=2)
Bu eng keng qo’llaniladigan masofa o’lchovidir va u haqiqiy qiymatli vektorlar bilan cheklanadi holos. U quydagi formuladan foydalanib, so’ralayotgan nuqta va qolgan boshqa nuqta orasidagi to’g’ri chiziqli masofani hisoblaydi.
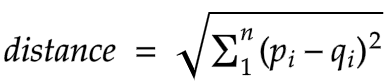
Manhattan distance (p=1)
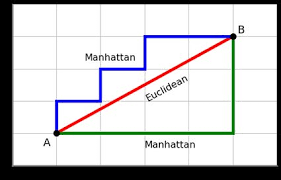
Bu yana bir mashhur masofa ko’rsatgichi bo’lib, ikki nuqta orasidagi mutlaq qiymatni o’lchaydi. Bu yana taxicab distance yoki city block distance ham deb ataladi. Chunki u odatda shahar ko’chalari orqali bir manzildan boshqasiga qanday o’tish mumkinligini ko’rsatadigan panjara bilan tasvirlaydi.
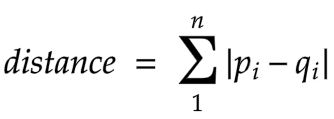
Minkowski distance
Bu masofa ko’rsatgichi Euclidean va Manhattan masofa ko’rsatgichlarining umumiylashganidir. Pastdagi formuladagi p parameteri boshqa masofa o’lchovini yaratishga imkon beradi. Bu formuladagi p 2ga teng bo’lganda
Euclidean distanceni ifodalaydi va p 1ga teng bo’lganda Manhattan distanceni ifodalaydi.
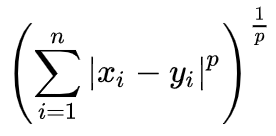
Hamming distance
Ushbu o’lchov odatda mantiqiy (boolean) yoki string vektorlar bilan ishlatiladi, vektorlar mos kelmaydigan nuqtalarni aniqlaydi. Natijada, u bir-biriga o’xshashlik ko’rsatgichi ham deb ataladi. Buni quyidagi formula bilan ifodalash mumkin.
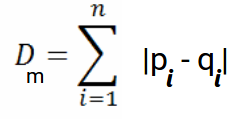
KNNni hisoblash: kni aniqlash
k-NN algoritmidagi hisoblashda k qiymat so’ralayotgan maxsus nuqtaning klasifikatsiyasini amalga oshirish uchun nechta qo’shni nuqtalarni tekshirish kerakligini bildiradi. Misol uchun, agar k=1 bo’lsa unda eng yaqin qo’shnisi bilan bir xil sinfga doir deb belgilanadi. kni belgilash muvozanatlovchi xarakat bo’lishi mumkin, chunki kga turli qiymatlar berish overfitting yoki underfittingga sabab bo’lishi mumkin. kning kichik qiymati yuqori farq(variance)ga lekin kechik qiyalik (bias) va kning katta qiymati kichik faqt(variance)ga lekin kechik qiyalik (bias)ga sabab bo’lishi mumkin. kning qiymatini belgilash kiritish ma’lumotlari(input data)ga bog’liq, chunki ko’plab istisno va ortiqcha keraksiz shovqinlar(noise)ga ega ma’lumot (data) kning yuqori qiymati bilan yaxshi natija berishi mumkin. Umuman olganda, chigallikni oldini olish maqsadida kning qiymatini toq son bilan ifodalash tavsiya etiladi va cross-validation taktikasi ma’lumotlar to’plamingiz uchun kning eng maqbul qiymatini tanlashda yordam berishi mumkin.
kning eng yaqin qo’shnilari va python
Yana ham chuqurroq o’rganish uchun siz Python va scikit-learn(yoki sklearn deb ataladi)dan foydalanib k-NN algoritmi haqida yana ham ko’proq bilib olishingiz mumkin. Ushbu link (link hozircha yopiq) orqali bu haqda to’libroq bilib olasiz
Machine learningda k-NN ilovalari
k-NN algoritmi turli ilovalarda, asosan sinflash masalarida qo’llanilgan. Quydagilar shular jumlasidandir.
- Ma’lumotlarni qayta ishlash (Data processing): Ma’lumotlar to’plami odatda ko’plab bo’shliqli qiymatlarga ega bo’ladi. Lekin, KNN algoritmi
missing data imputation(yo’qolgan ma’lumotlarni to’ldirish)deb ataluvchi ishlov jarayonida bu yo’qolgan qiymatlarni aniqlaydi.
KNN algoritming afzalliklari va kamchiliklari
Xar qanday machine learning algoritmlari singari, k-NN ham o’zining kuchli va zaif tomonlariga ega. Qilinayotgan proyekt (loyiha) yoki applicaiton(ilovaga) ga qarab, k-NN to’g’ri yoki noto’g’ri tanlov bo’lishi mumkin.
Afzalliklari
-
Qo’llash oson: Algoritmning soddaligi va aniqligini hisobga olsak, u yangi data scientistlar birinchi o’rganadigan sinflovchi(classifier)lardan bittasi sanaladi.
-
Oson moslashadi: Yangi o’qitish namunalari (training samples) qo’shilganda, algoritm har qanday yangi ma’lumotni hisobga olish uchun mostlashadi, chunki hamma o’qitish ma’lumotlarini xotirada saqlaydi.
-
Oz sonli hyperparameterlar: KNN faqat k qiymatni va masofa ko’rsatgichini talab qiladi, bu boshqa machine learning algoritmlari bilan solishtirganda juda ozdir.
Kamchiliklari
-
O’lchomlilik lanati (Curse of dimensionality): KNN algoritmi o’lchamlilik lanatining qurboni bo’lishga moyil bo’ladi. Bu degani, ko’p o’lchamli kirish ma’lumotlari bilan ishlaganda yaxshi natija bermaydi. Bu shuningdek bazan peaking phenomenon ham deb yuritilib, bunda algoritm eng maqbul feature(xususiyat)lar soniga erishgandan so’ng qo’shimcha features(xususiyatlar) sinflash xatolarining miqdorini oshirib yuboradi, ayniqsa namuna hajmi kishik bo’lganda yanaham ko’proq kuzatiladi.
-
Overfittingga moyil bo’lishlik: “O’lchamlilik lanati” sababli, KNN overfittingga ko’proq moyil bo’ladi. Xususiyat(feature)larni tanlash va o’lchamlarni kamaytirish usullari buning oldini olish uchun qo’llanilsa-da, kning qiymati ham modelning xatti-xarakatiga ta’sir qilishi mumkin. kning past qiymatlari ma’lumotlarga haddan tashqari moslashishi mumkin (overfitting ro’y berishi mumkin). Holbuki, kning yuqori qiymatlari bashorat qilingan qiymatlarni silliqlashga moyilroq bo’ladi, chunki u kattaroq hudud yoki neighborhooddagi qiymatlarning o’rtachasini hisoblaydi.